
RDS DuckDB + QuickBI 企业套餐,8核32GB + QuickBI 专业版
本文介绍了PyTorch深度学习中四种核心损失函数及其应用场景。交叉熵损失(CrossEntropyLoss)适用于多分类任务,二进制交叉熵损失(BCELoss)专用于二分类问题,KL散度损失(KLDivLoss)用于衡量概率分布差异(如VAE模型),均方误差(MSELoss)则是回归任务的基础损失函数。通过具体代码示例(如图像分类、广告点击预测、房价预测等),文章展示了每种损失函数的PyTorch实现方式,并比较了不同损失函数的适用场景和计算特点,帮助读者根据任务需求选择合适的损失函数。
在深度学习的广阔领域中,如果说神经网络是结构精密的引擎,那么损失函数(Loss
Function)就是指引引擎方向的罗盘和灵魂。它承担着至关重要的任务:量化模型的预测结果与
真实标签之间的差距,并将这个差距转化为可供优化器使用的梯度,驱动着整个反向传播过程。
一个优秀的模型离不开一个恰当的损失函数。它不仅决定了模型的学习目标,更直接影响了模型的
收敛速度和最终性能。PyTorch 作为最主流的深度学习框架之一,提供了丰富且高效的损失函数模
之间有何不同?我该在什么场景下使用哪一个?本文将脱离枯燥的理论推导,以 PyTorch 实战代
码和具体的应用场景为核心,带你深入理解几个在深度学习实战中最为关键的损失函数。我们将通
【3】KL 散度损失 (KL Divergence Loss):在变分自编码器(VAE)等生成模型中衡量分布差异的
读完本文,你将不仅知道如何调用 PyTorch 中的损失函数,更能理解它们背后的数学意义和应
交叉熵在信息论中用于度量两个概率分布间的差异性。将上述相对熵(KL散度)公式拆开,可以
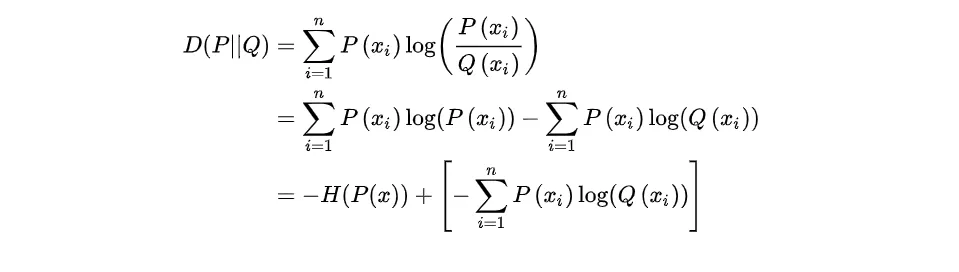

因此,对于一个离散随机变量的两个概率分布 P和 Q来说,它们的交叉熵定义为:
在机器学习训练时,输入的数据和它对应的标签(比如图片是 “猫” 还是 “狗”)都是确定的。这就
意味着,真实的概率分布其实是 “固定” 的 —— 比如某个样本的真实标签是 “猫”,那真实分布就是
“猫的概率 = 100%,狗的概率 = 0%”。既然真实分布固定,那它的熵(衡量不确定性的那个值)也
会是一个固定不变的数。而交叉熵的公式里,包含了两部分:一部分是真实分布和预测分布的 “相
对熵”(KL 散度,衡量两者差异),另一部分就是真实分布的熵(那个固定的数)。所以,交叉熵
其实就等于 “相对熵 + 一个固定值”。因为固定值不影响 “谁大谁小” 的比较,所以交叉熵和相对熵
一样,都能用来衡量预测分布和真实分布的差异 —— 值越小,说明预测得越准。而且交叉熵的计
算公式比相对熵更简单,算起来方便。所以机器学习里,大家更爱用交叉熵当损失函数来算


二分类中的损失函数比较简单这里就不多介绍了,这里我们来看一下多分类中的损失函数。
下面这个是一个图片分类的问题,图片中有


 官方微信
官方微信


 官方微博
官方微博




